Welcome to FakeSound demo website.
You can see some deepfake general audio here.
Certain semantic segments of them have been
located by the audio text grounding model and regenerated using generative models.
You can see some deepfake general audio here.
Certain semantic segments of them have been
located by the audio text grounding model and regenerated using generative models.
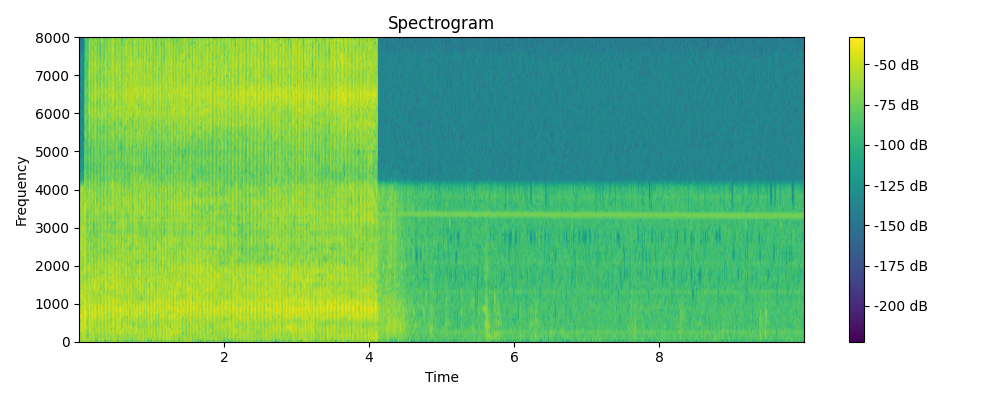
Ground truth
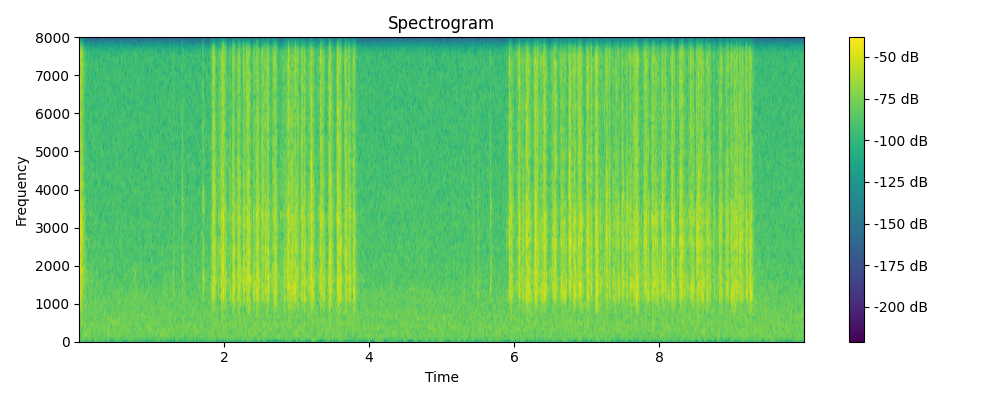
Grounded & Masked
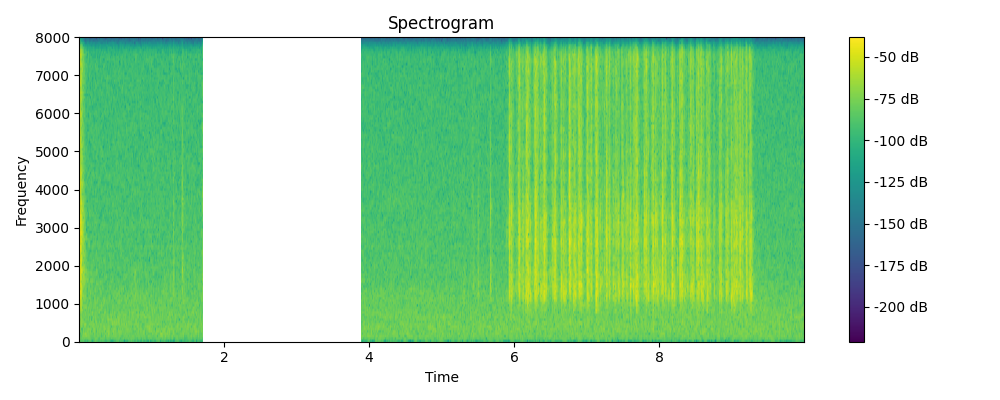
Regenerated
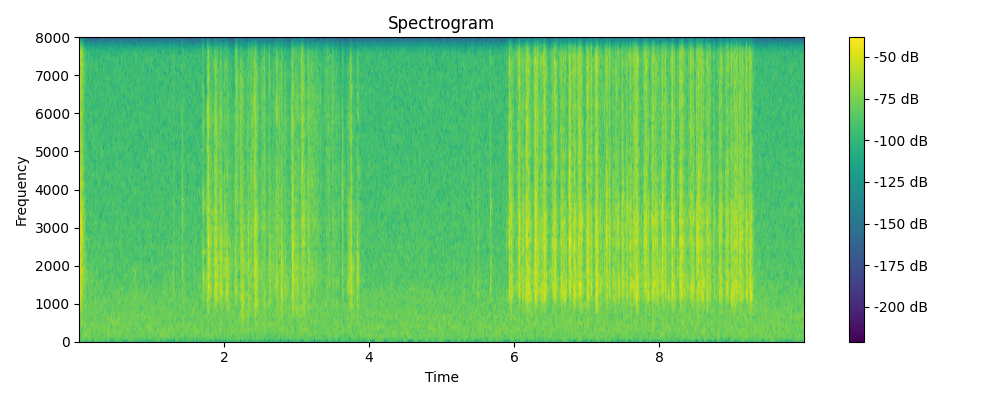
Ground truth
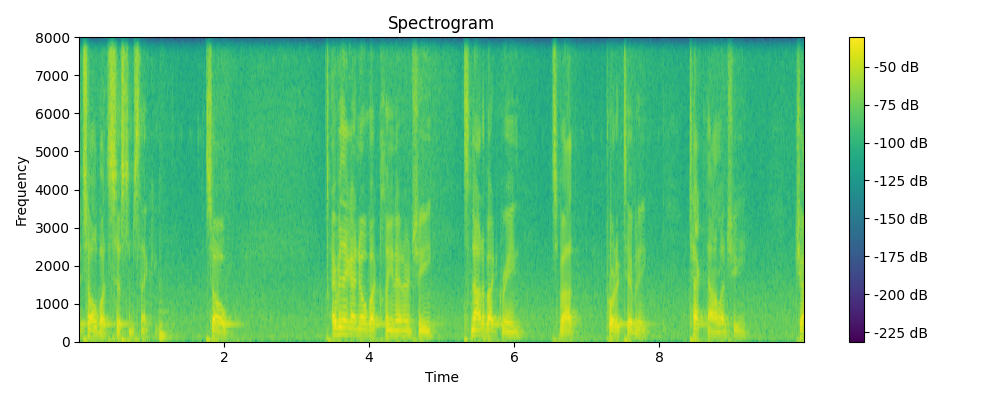
Grounded & Masked
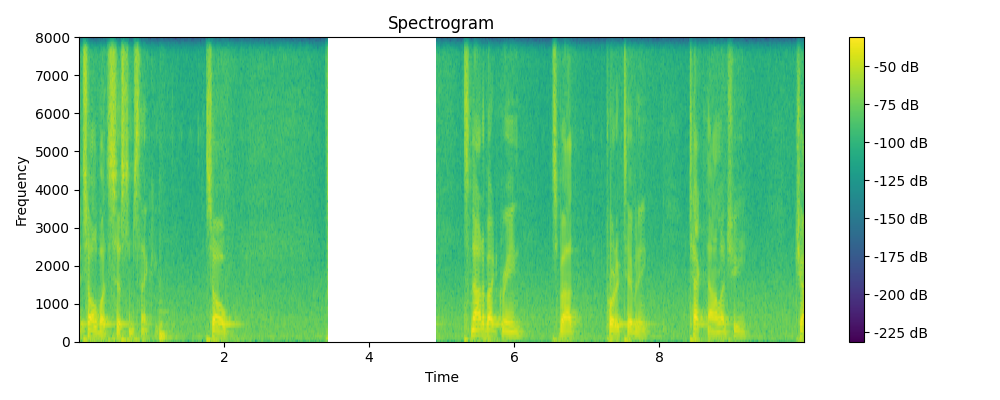
Regenerated
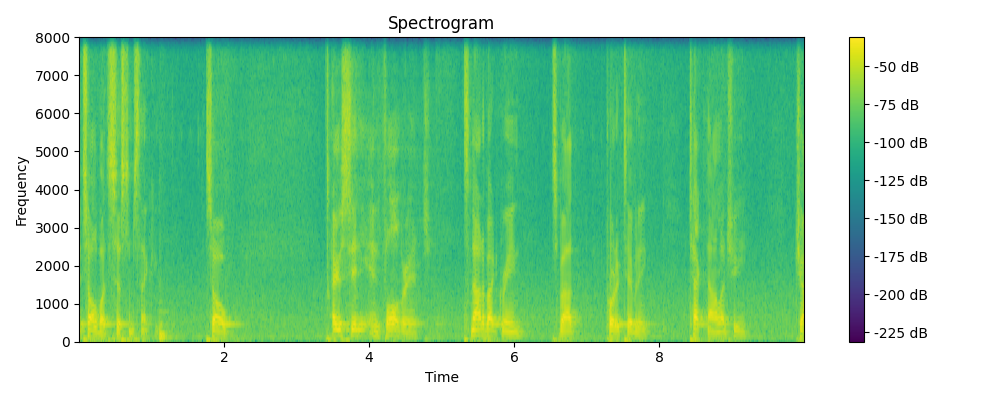
Ground truth
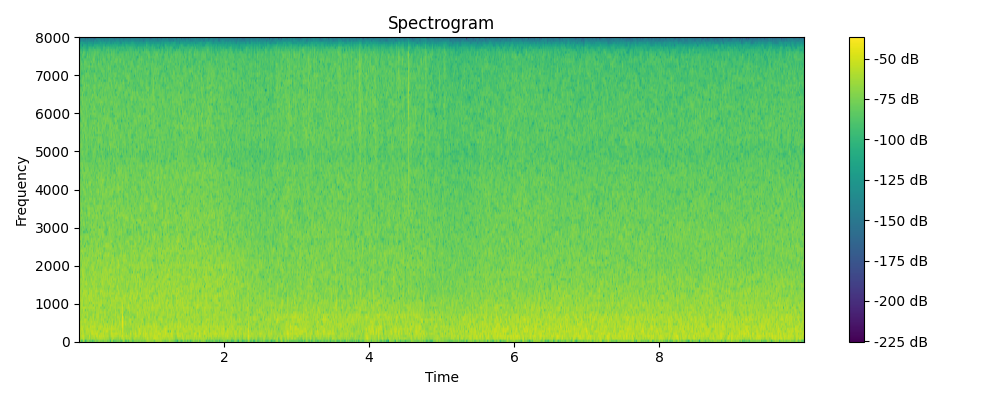
Grounded & Masked
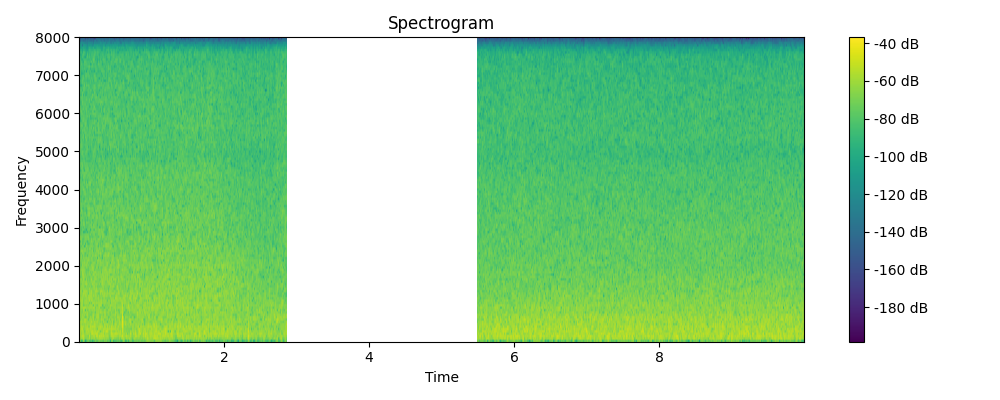
Regenerated
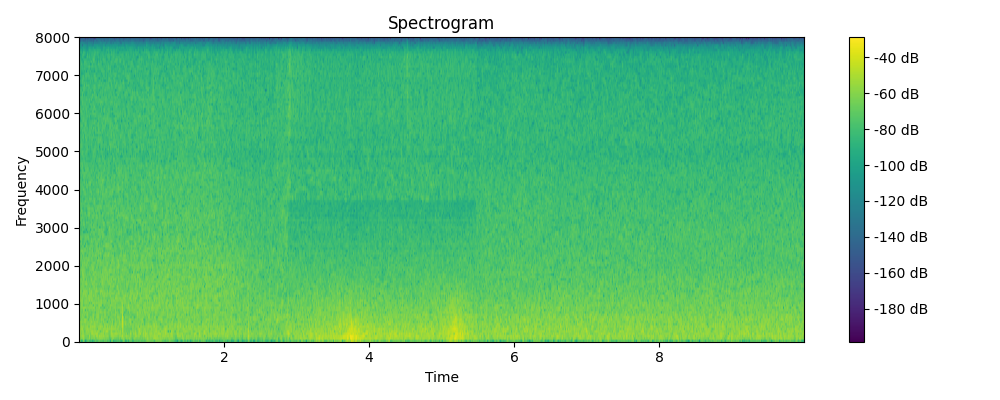
Ground truth
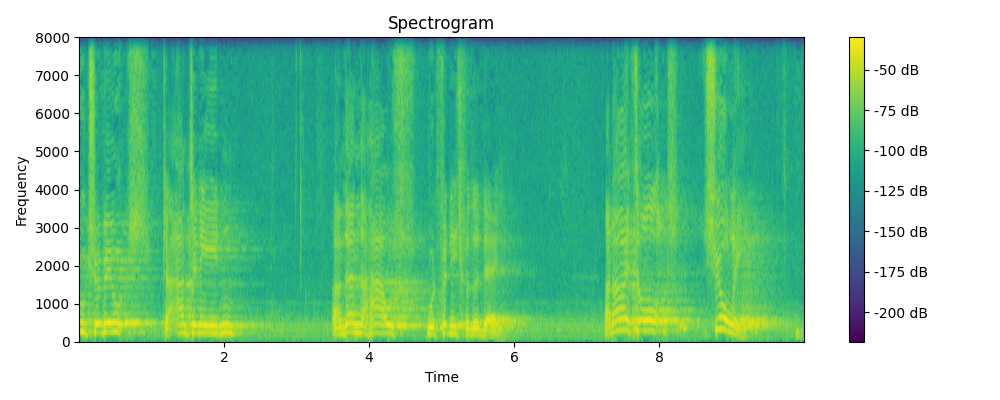
Grounded & Masked
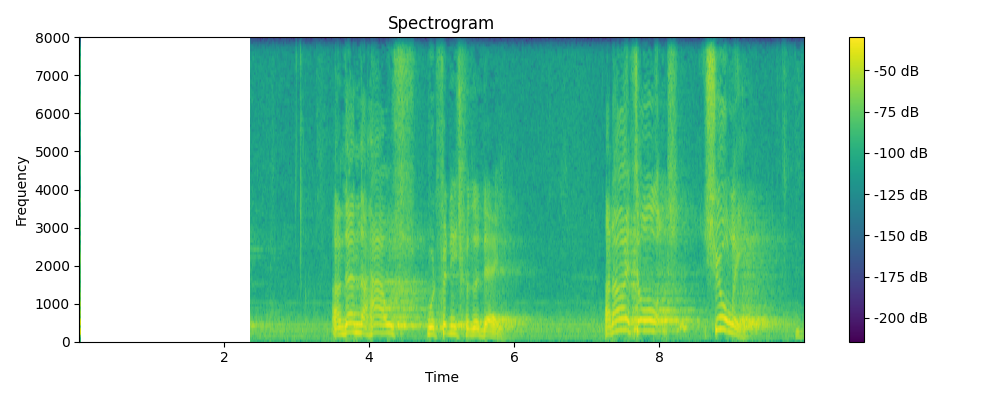
Regenerated
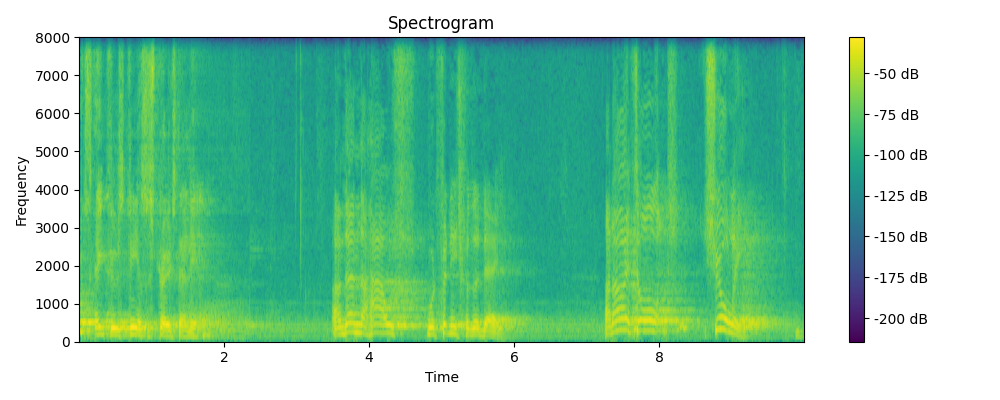
Ground truth
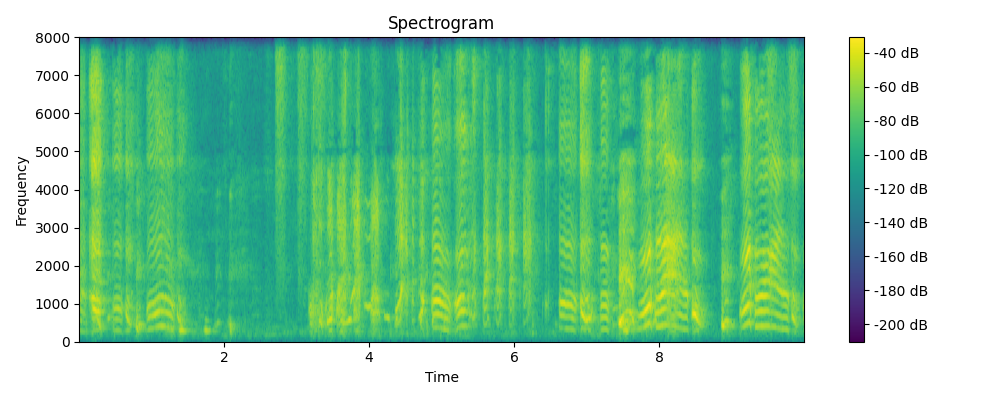
Grounded & Masked
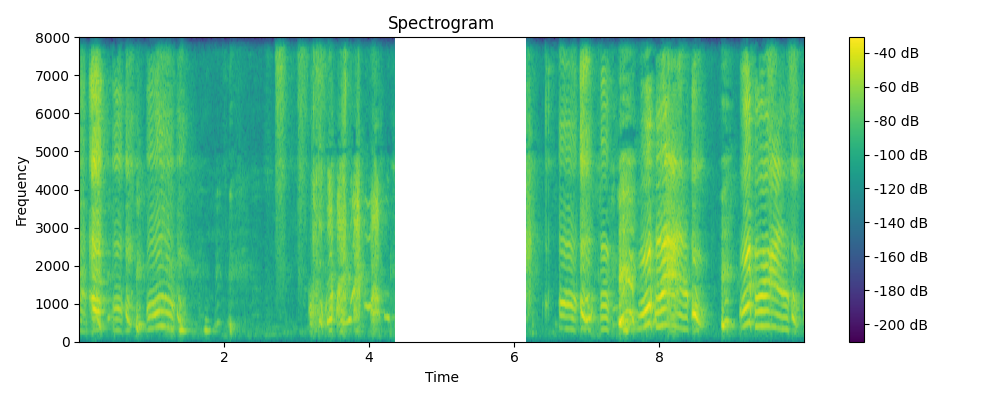
Regenerated
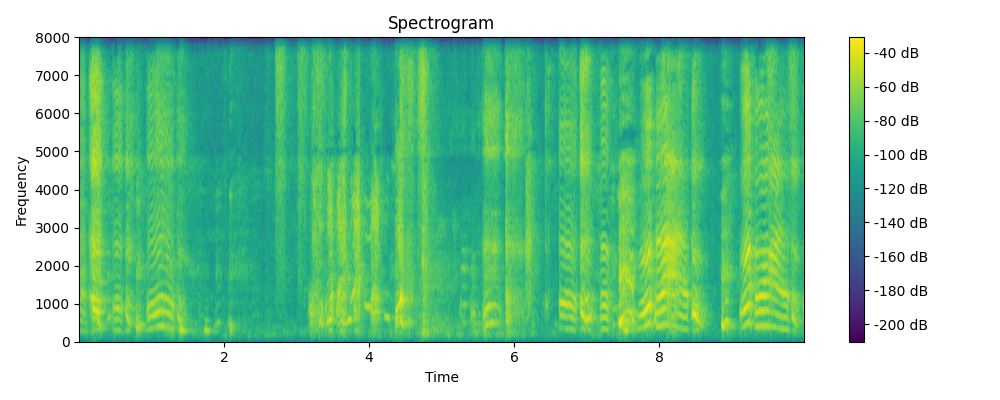
Ground truth
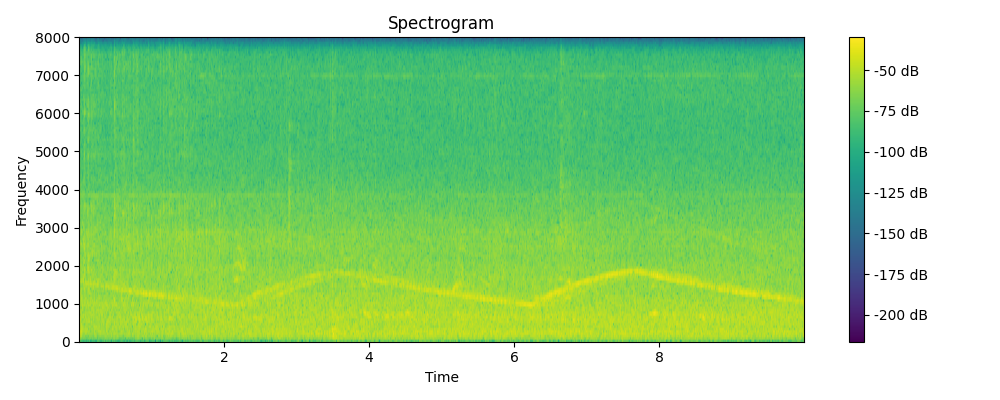
Grounded & Masked
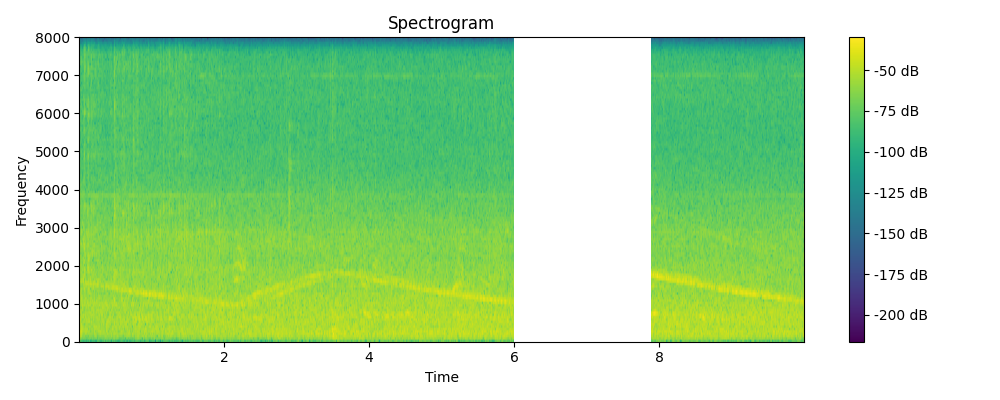
Regenerated
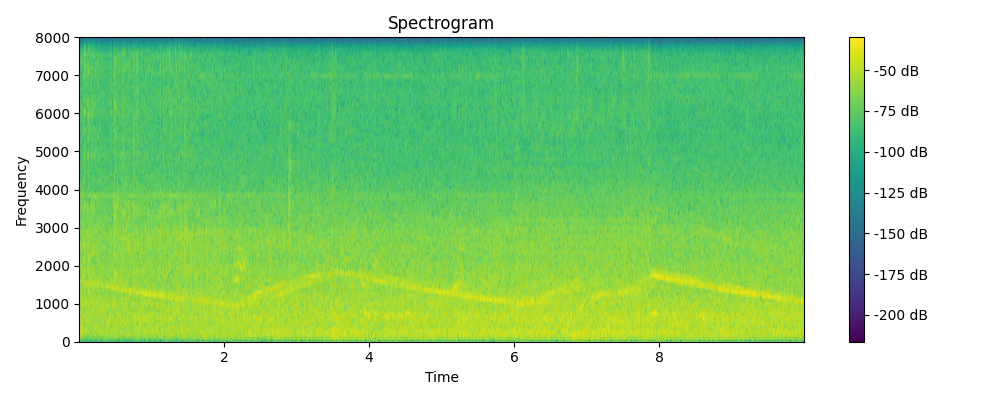
Ground truth
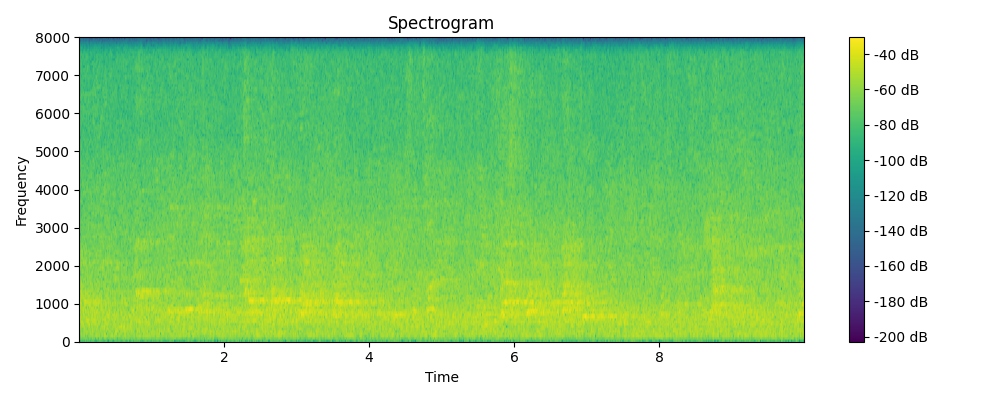
Grounded & Masked
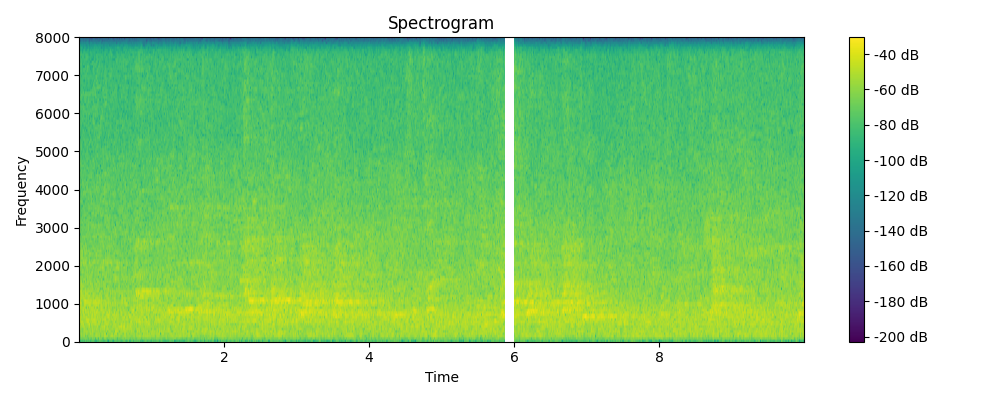
Regenerated
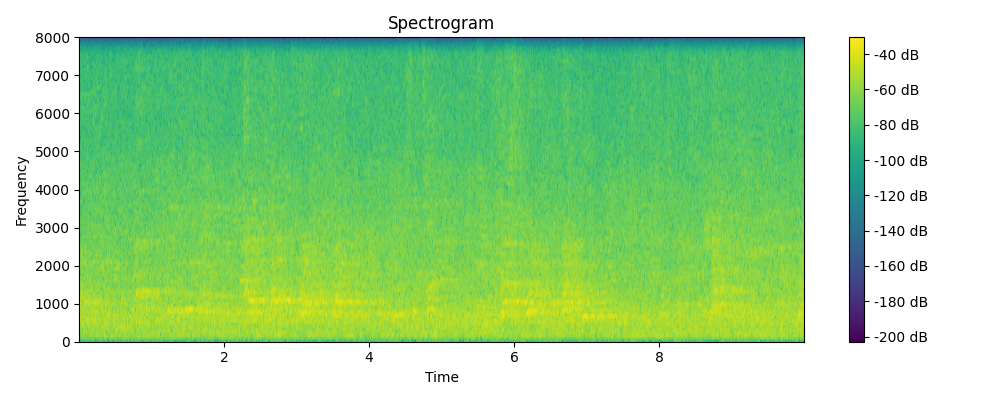
Ground truth
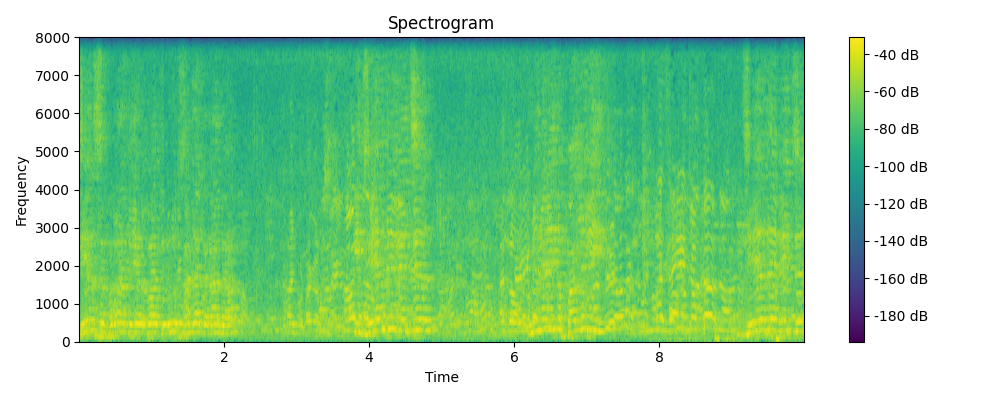
Grounded & Masked
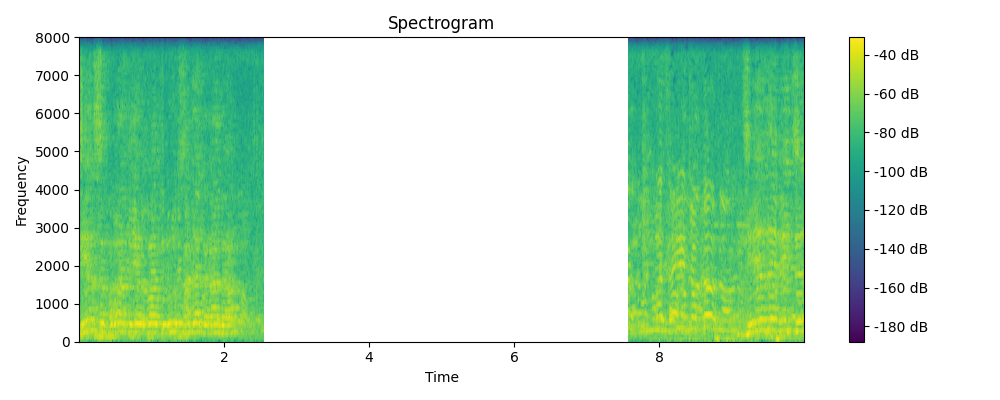
Regenerated
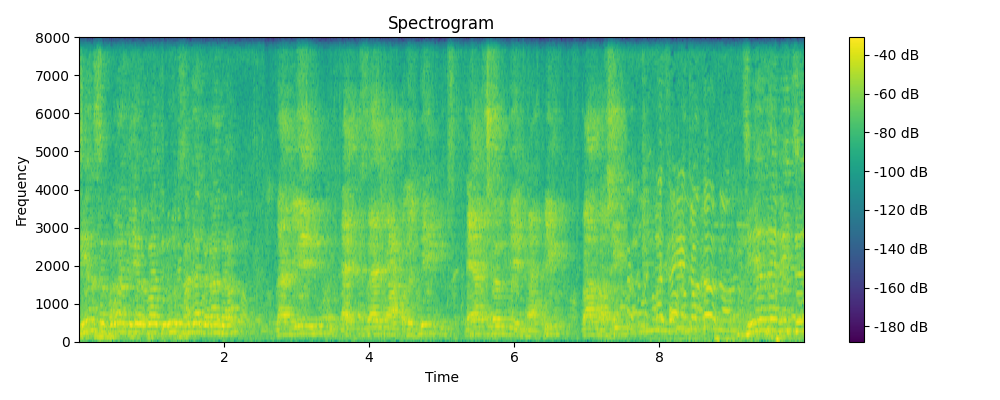
Ground truth
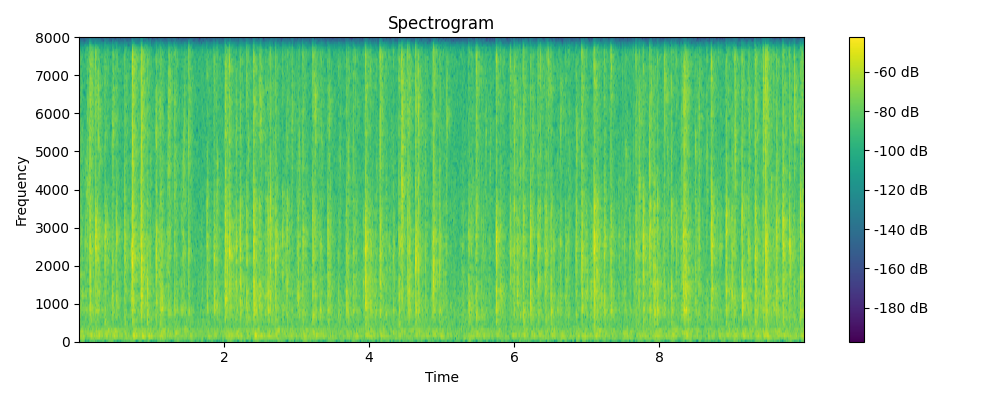
Grounded & Masked
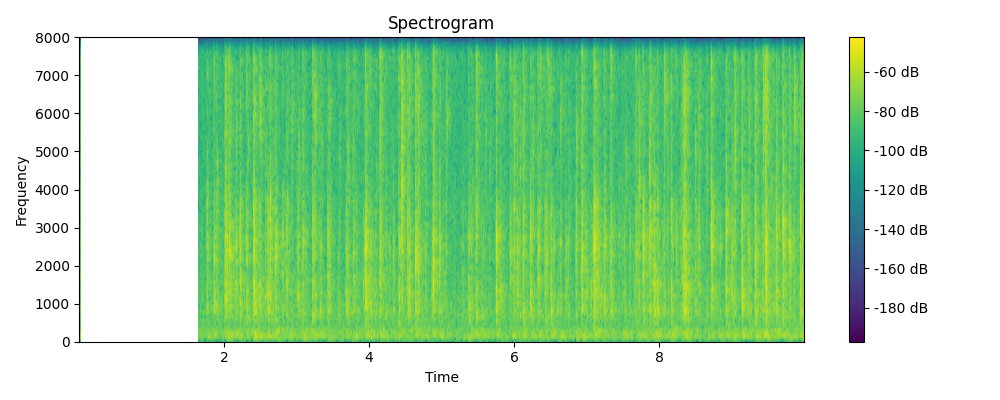
Regenerated
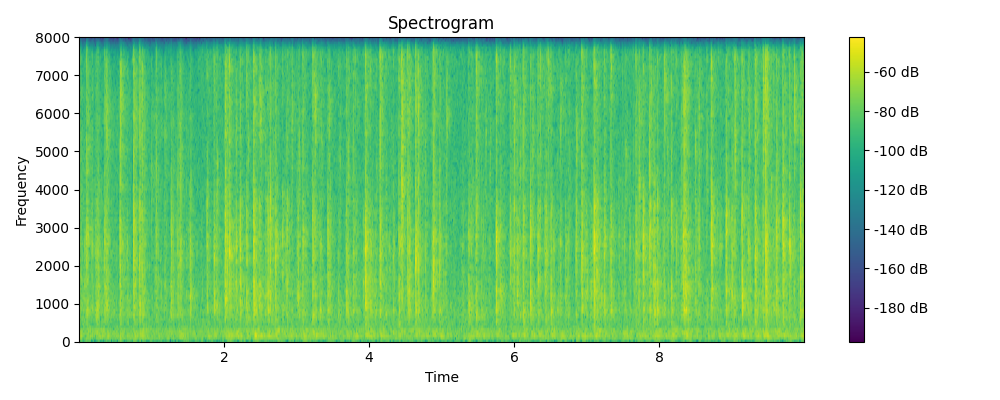
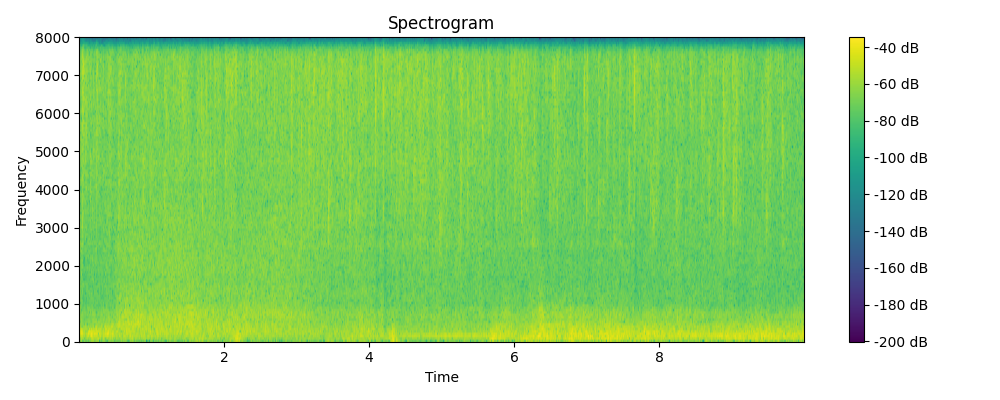
Ground truth
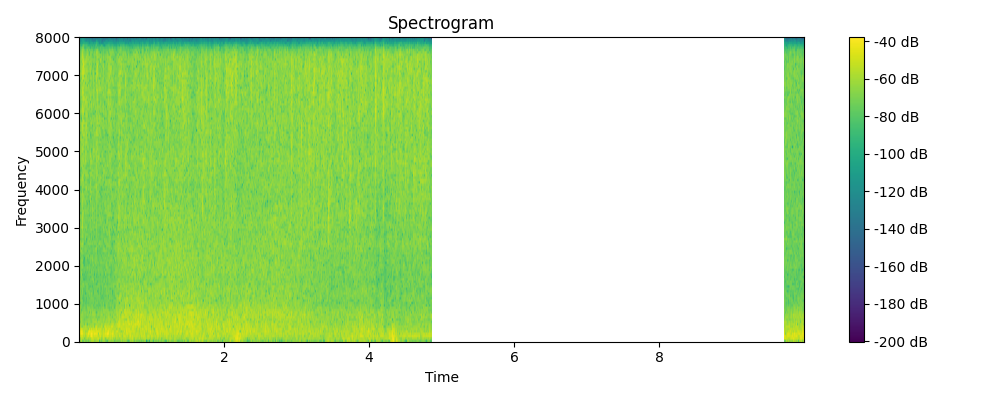
Grounded & Masked
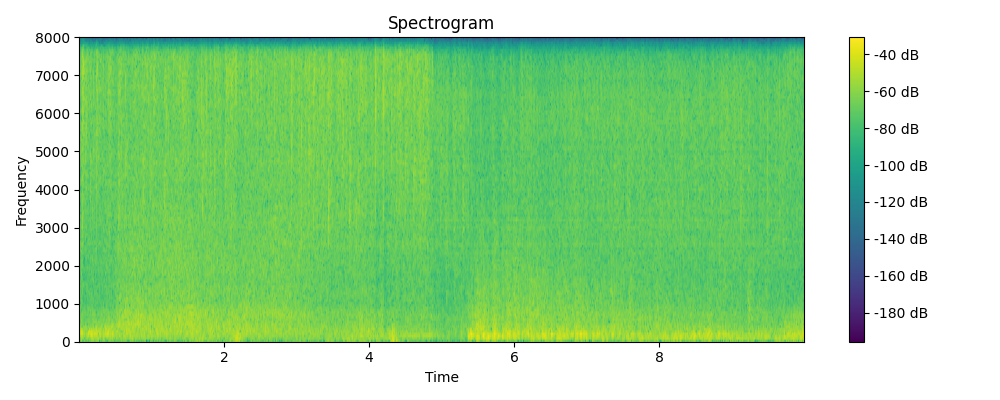
Regenerated
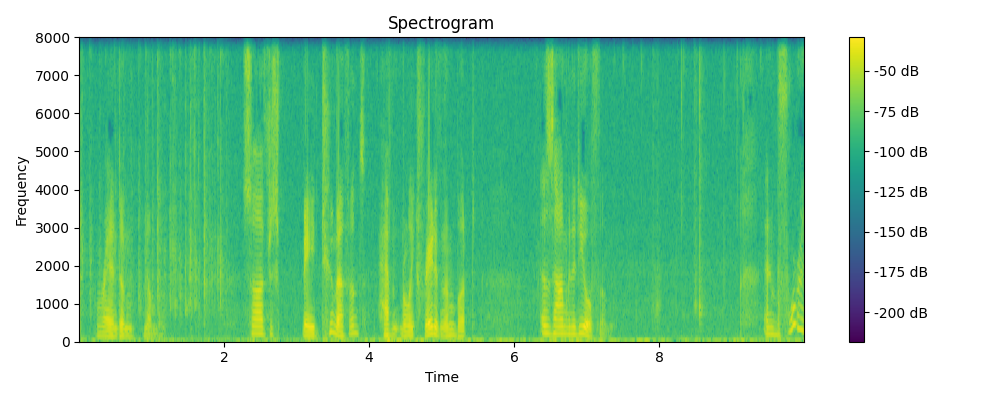
Ground truth
Grounded & Masked
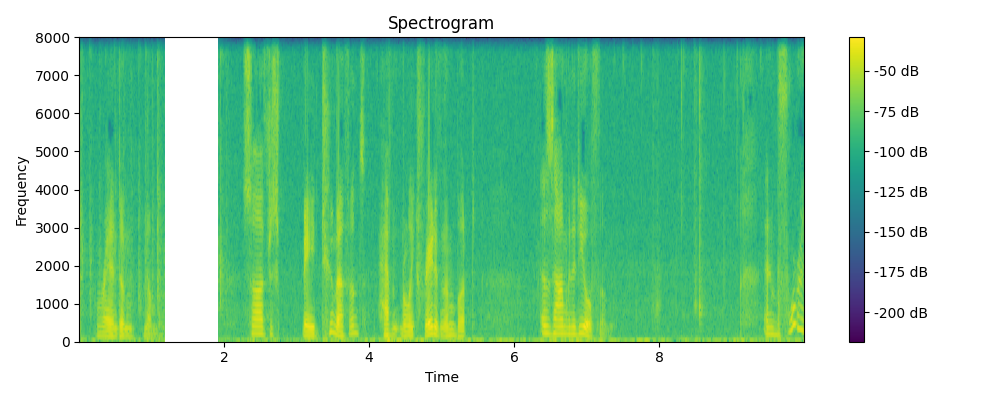
Regenerated
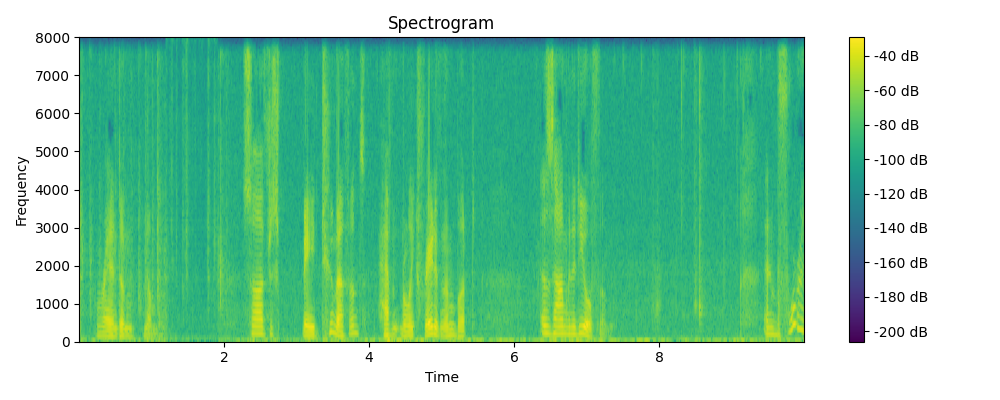
Ground truth
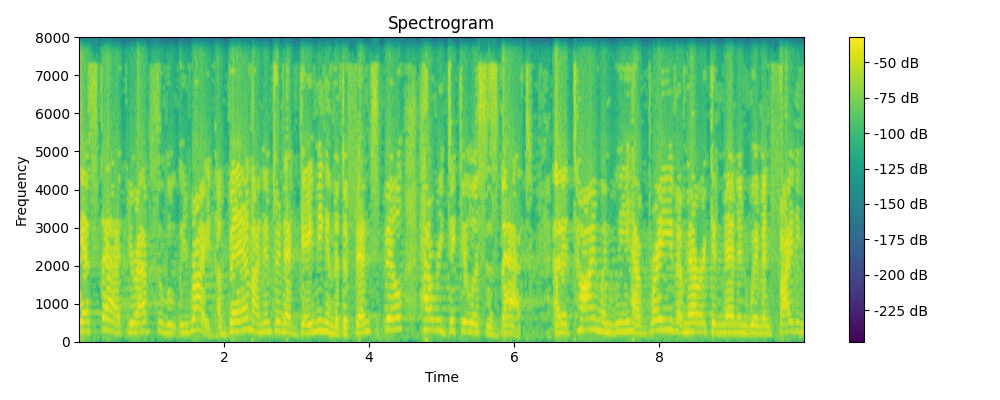
Grounded & Masked
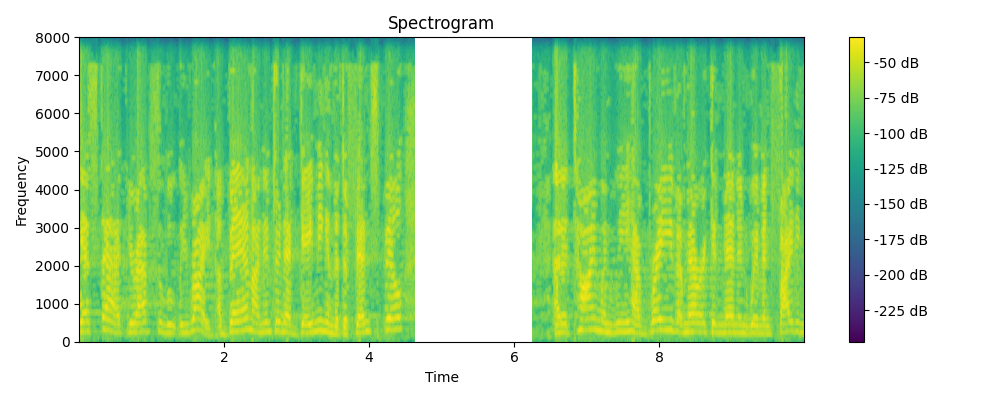
Regenerated
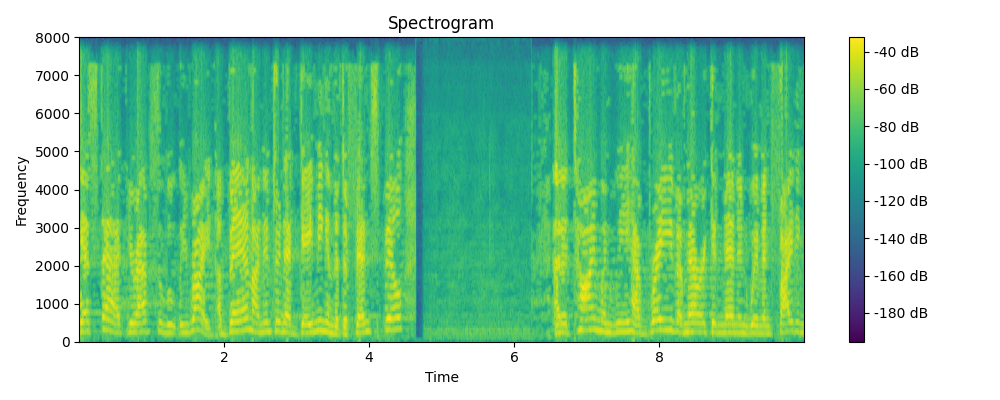
Ground truth
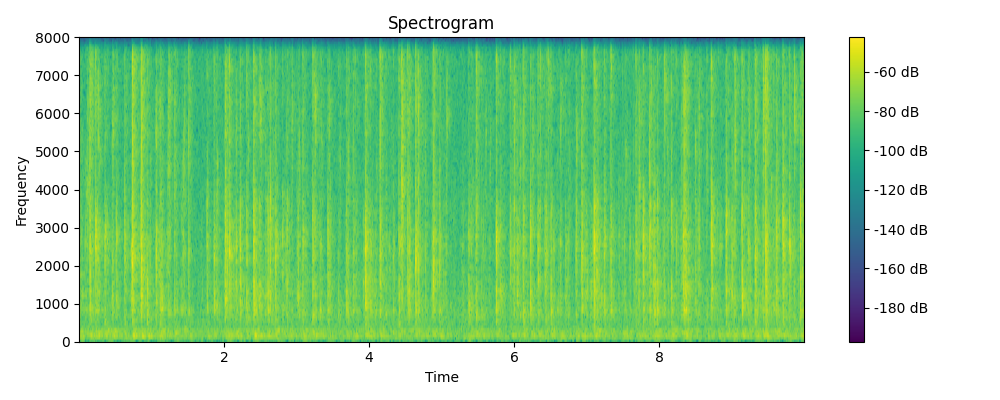
Grounded & Masked
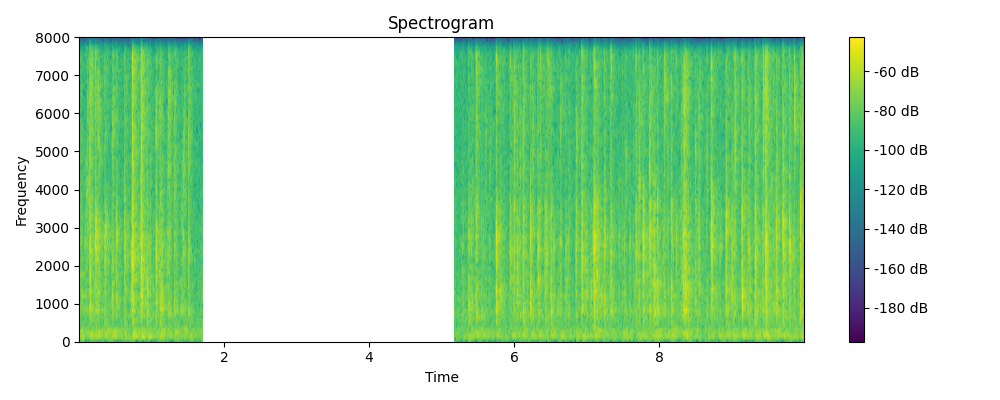
Regenerated
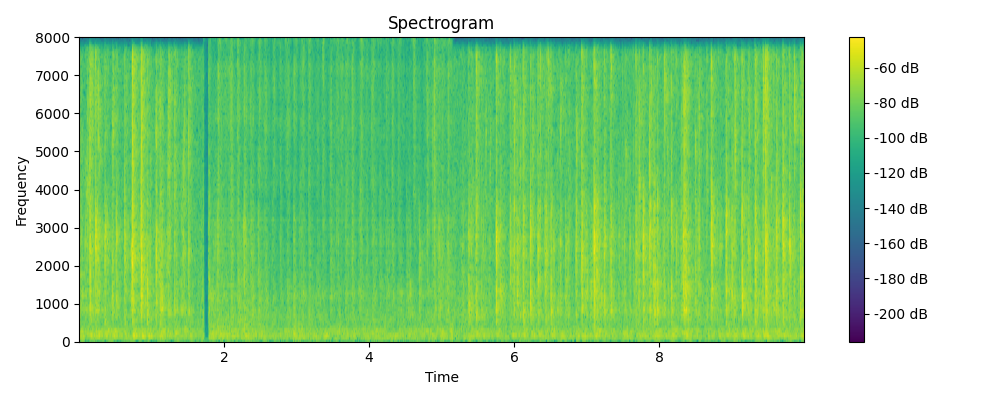
Ground truth
Grounded & Masked
Regenerated